

Imagine this, You're looking at what seems like a healthy database—vendors, materials, customers all neatly lined up—when you notice something odd. The same vendor has three IDs. The same spare part appears under slightly different names. A material you stopped using ages ago? Still sitting there, duplicated under a new code.
This isn't a minor glitch. It's data duplication, and it quietly chips away at efficiency, trust, and money.
Here's the hard truth: duplicates aren't just annoying, they distort decisions. They skew analytics, trigger payment errors, inflate inventory, and even lead to compliance risks. And as your data grows, they multiply like weeds.
So, what if you could spot duplicates before they ever pollute your systems?
That's where Duplicate Check in MDO's Data Intelligence Workbench (DIW) steps in, like a sharp-eyed data detective for your enterprise (think DIW 007).
Meet DIW's Duplicate View!
DIW isn't just about data cleansing, it's about data clarity and remediation.
Within DIW lies a powerful feature called the Duplicate View, a result of running a Duplicate Check schema on any dataset. Instead of treating duplicates as an afterthought, DIW treats them as a core data quality issue.
Unlike typical tools that only catch identical matches, DIW uses a layered, intelligent approach, mixing exact matches and fuzzy logic to catch even sneaky near-duplicates that look different but mean the same thing.
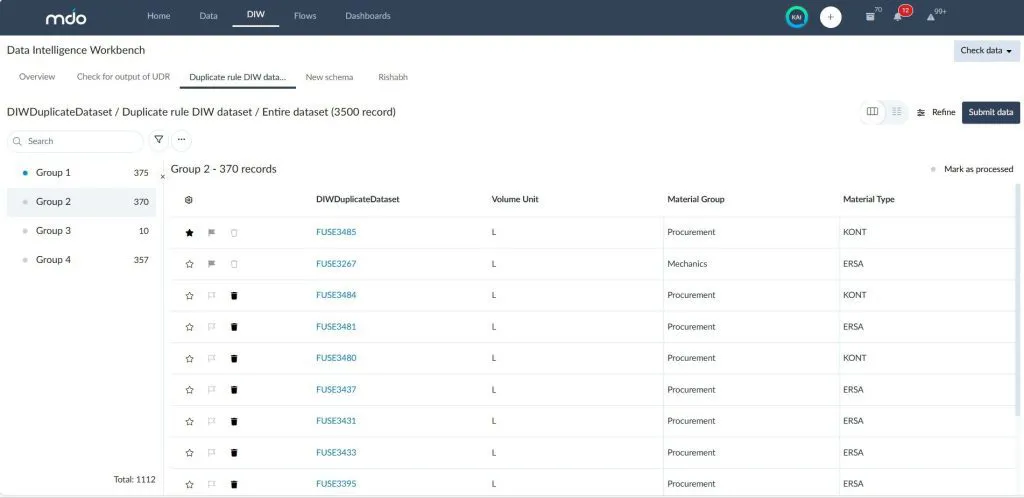
Note: The image is a sample of a duplicate dataset in DIW.
Building the Rules Behind It All
Duplicate Rules are the engine that keeps the process running smoothly. They let you define which fields to check (like Name, Material Type, or Country), choose between Exact or Fuzzy matching, assign weightage to each field, set the similarity threshold, and determine the system's response—Warning or Error—if a duplicate is found. You can even confine checks to specific conditions, such as vendors from Australia or materials tagged as spare parts, making the process both efficient and context-aware.
How the Hunt Begins: Setting the Scope
The process starts with defining a data scope.
Instead of checking your entire data ocean, you tell DIW where to dive. This targeted schema-based approach keeps things sharp, fast, and relevant.
Then, you attach a Duplicate Rule from your business rule library to that scope. This rule defines which fields should be checked, what counts as a duplicate, and how strictly DIW should judge it.
Because let's face it — what counts as “duplicate” for a spare part isn't the same as for a vendor, right?
Lexeme Logic: Teaching DIW to Read Between the Lines
Here's where it gets clever.
Before it even starts comparing records, DIW runs a Lexeme Value Handling step, basically teaching itself to normalize words.
For example, “play”, “played”, and “playing” are understood as the same root concept. It removes special characters, ignores filler words, and standardizes formats.
Why does this matter? Because real-world data is messy, and DIW is smart enough to clean the mess before judging it.
Weighted for What Matters: Prioritizing the Right Fields
Once records are ready, DIW doesn't just check them randomly. It uses Weighted Sorting — that works in two ways. First, configurable weightages allow records to be prioritized based on the fields you choose and their assigned importance, with the configured order resolving ties — giving you flexibility to reflect what matters most to your business. Second, business rule adherence ensures sorting aligns with defined rules. Say Material Type matters more than Material Description. You can assign weightages (like 55% vs 20%), and DIW will sort and compare records accordingly.
This means you're not just catching duplicates — you're catching the right duplicates that actually impact your business.
Exact or Fuzzy? DIW Does Both
This is where the real detective work begins.
- Exact Matching: DIW first groups records that are absolutely identical in the chosen fields.
- Fuzzy Matching: Fuzzy Matching goes beyond exact matches by detecting near-duplicates and subtle variations in records, ensuring cleaner, more reliable data without manual effort.
So, even if two records differ by a typo or have slightly jumbled words, DIW can still catch them.
For instance…I bet you've seen “XYZ Company Pvt Ltd” and “XYZ Company Private Limited” live side by side in a system for years! That stops here.
Taking Control: Manual Master, Survivor, and Deletion Tagging
Here's where most tools stop, but DIW goes further. Instead of locking you into its automatic choice, it puts you in control. In the Duplicate View output, you can review each group of potential duplicates, mark the true Master record (Golden Record) with a star, tag the valid Survivors with a flag, and mark the rest for Deletion with the bin — giving you the final say on what stays and what goes.
Want to override DIW's auto-choice? Go ahead.
Once you submit your selections, they're routed through approvals (if configured), keeping the whole process auditable, governed, and transparent.
This means you control which version of the truth survives, and everyone across the business sees one clean, trusted record.
Safety Nets and Smart Locks
DIW also protects you from collisions. If any record is part of an active change request, it's locked from editing until that request is closed — preventing conflicting changes or data corruption.
And if One View is configured, you can even click any record to open its full 360° profile while reviewing duplicates — so you're never making decisions blind.
Why Checking for Duplicates Matters?
Catching duplicates isn't just about clean data. It's about everything that depends on it:
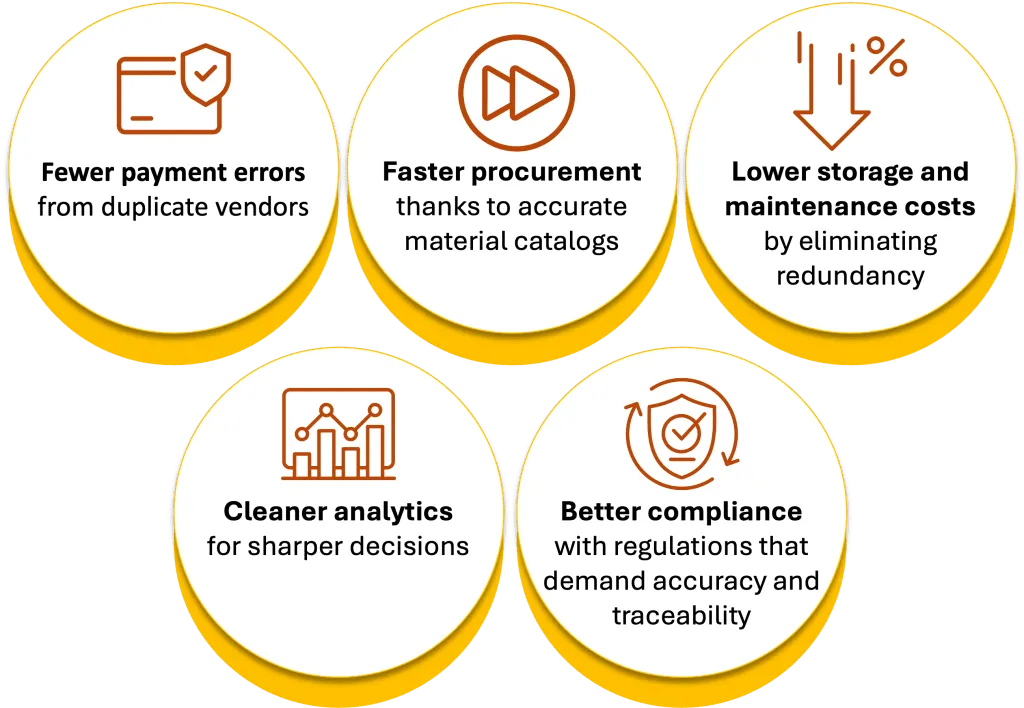
And the Benefits of Duplicate Check?
The Duplicate Check in MDO ensures that data remains accurate and reliable by preventing redundant records, while enhancing overall data quality by reducing errors, inconsistencies, and inaccuracies. It boosts efficiency by automating duplicate identification, cutting down on manual effort, and streamlining data management processes. At the same time, it helps organizations save costs associated with maintenance and storage, supports better decision-making with high-quality, non-redundant data, and maintains consistency across departments and systems. Additionally, it plays a critical role in regulatory compliance, safeguarding sensitive information and ensuring that reporting and analytics are trustworthy and reliable.
Some more up-sides of this feature, .
The Duplicate View includes clear visual cues — icons to mark records as Master, Survivor, or for Deletion, validation banners that prompt users if required fields (like Activate/Deactivate) are missing or duplicated, etc. Tooltips on the Submit Data tab offer instant guidance, ensuring no step is missed. Every action a user takes, from tagging a golden record to marking duplicates for removal, is logged, routed through approvals if required, and fully auditable, making the clean-up both effortless and compliant.
Let's understand the feature with the help of a use case, .
A mining company manages operations across multiple sites and sources materials from many vendors. Over time, their database has grown large and cluttered. Vendor names have slight variations, contact details are inconsistent, and material descriptions don't always match. Duplicates start piling up, making it harder to trust the data.
This is where MDO Duplicate Check comes in. It scans vendor and material records to identify potential duplicates and organizes them for review. Users can pinpoint the most accurate records, remove redundant entries, and make sure every vendor and material entry is correct.
The results are clear: data accuracy improves, procurement processes run smoother with fewer discrepancies, and payment errors decrease, improving financial management. Most importantly, the company now has trustworthy, consistent data, giving leaders the confidence to make informed decisions. MDO turns a messy, duplicate-filled database into a reliable and actionable resource.
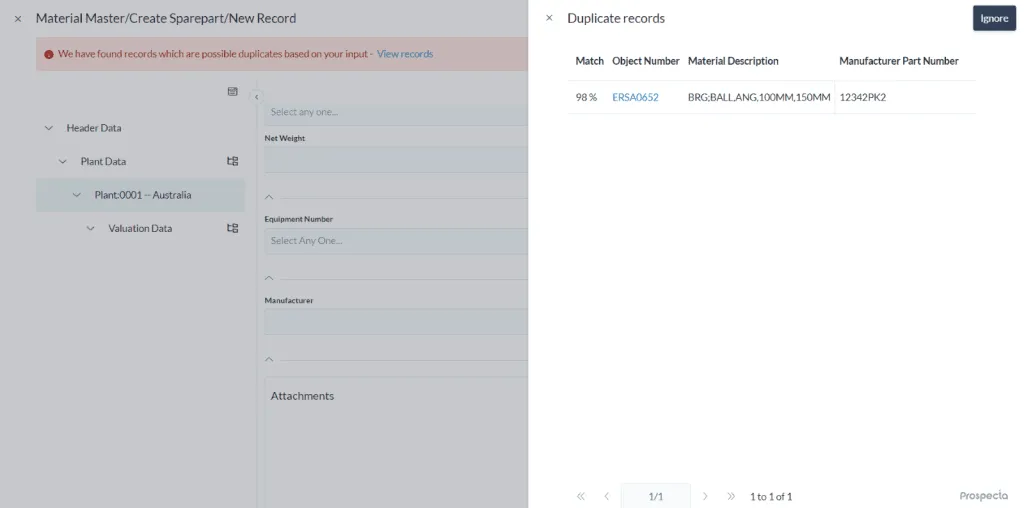
Note: The image is a sample of the listed potential duplicates of the mining company
Wrapping it up!
How much hidden chaos could be sitting in your data right now?
How many business decisions are being made on the back of duplicates pretending to be facts?
With Duplicate Check in DIW, you don't have to wonder.
You can find, fix, and prevent duplicates, .all in one governed, intelligent sweep.
And when your data is clean, your business moves faster, smarter, and stronger.
